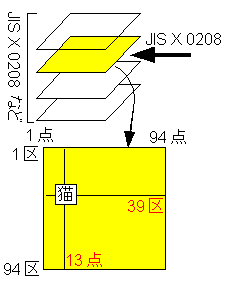
 側偍丄戞3丄戞4悈弨娍帤側偳偼忋婰偺1屄偺敔偱偼擖傝偒傜側偄傢偗偱偡丅偙傟傪夵慞偟丄Shift-JIS僐乕僪偵傕峫椂偟偨JIS X 0208傪奼挘偟偨婯奿偱偁傞JIS X 0213(2000擭嶔掕)偱偼丄敔傪偄偔偮傕梡堄偡傞偙偲偵偟傑偟偨丅偦傟偧傟偺敔傪乽柺乿偲屇傃偦偺拞偵嬫偲揰偑偁傞偲偄偆峔憿偱偡丅傑偁丄98偱偼婥偵偟側偔偰偄偄偺偱偡偑丅
側偍丄戞3丄戞4悈弨娍帤側偳偼忋婰偺1屄偺敔偱偼擖傝偒傜側偄傢偗偱偡丅偙傟傪夵慞偟丄Shift-JIS僐乕僪偵傕峫椂偟偨JIS X 0208傪奼挘偟偨婯奿偱偁傞JIS X 0213(2000擭嶔掕)偱偼丄敔傪偄偔偮傕梡堄偡傞偙偲偵偟傑偟偨丅偦傟偧傟偺敔傪乽柺乿偲屇傃偦偺拞偵嬫偲揰偑偁傞偲偄偆峔憿偱偡丅傑偁丄98偱偼婥偵偟側偔偰偄偄偺偱偡偑丅NEC PC-9800僔儕乕僘偺摿挜偺傂偲偮偵丄娍帤昞帵傪僴乕僪僂僃傾偵傛偭偰崅懍偵昞帵偱偒傞偲偄偆揰偑偁傝傑偟偨丅偦偺僼僅儞僩僷僞乕儞傪奿擺偟偨ROM偑娍帤ROM偱偡丅偙偺婰帠偱壗傪弎傋偨偄偐偲偄偆偲丄僔僼僩JIS偱奿擺偝傟偨暥帤楍傪VRAM偵彂偒偙傓偲偄偆偨偩偦傟偩偗偺偙偲偱偡丅偖偖偭偰傕傑偲傔偰偍傜傟傞曽傪尒偮偗傜傟傑偣傫偱偟偨偺偱(^^;丅扤偑彂偄偰傕椙偄傫偱偟傚偆偗傟偳傕丄帺暘偺摢偺惍棟傕寭偹偰偟傑偟偨丅傑偨丄PC-9801弶戙側偳偺敪攧帪偺偙偲偼椙偔抦傜側偄偺偱丄帪戙峫徹乮娋乯偼娫堘偭偰偄傞壜擻惈偑偁傝傑偡丅ISO2022-JP偼98敪攧傛傝悘暘屻偵婯奿壔偝傟偨偺偱丄杮棃偼帪戙偑慜屻偡傞傢偗偱偡偑丄尰忬偱偼偙偪傜傪斾妑懳徾偵偟偨傎偆偑棟夝偟傗偡偄偺偱嵹偣偰偁傝傑偡丅
擔杮岅偺暥帤僐乕僪偲偄偆偲丄僔僼僩JIS丄EUC丄Unicode丄JIS丄側偳偲偄偆庬椶傪帹偵偟偨偙偲偑偁傞偐偲巚偄傑偡丅晛抜Windows傗DOS摍偱娍帤崿偠傝偺僥僉僗僩僼傽僀儖傪曐懚偡傞偲丄Shist-JIS僐乕僪偱奿擺偝傟傑偡丅婔暘崅婡擻側僥僉僗僩僄僨傿僞乮巹偼TERAPAD傪垽梡偟偰偍傝傑偡丅乯偱偼丄暥帤僐乕僪偺庬椶傪慖傇偙偲傕弌棃傑偡丅側偍丄偙偺HTML暥彂偼Shift-JIS偱彂偐傟偰偍傝傑偡丅愄EUC偱曐懚偟偨偙偲偑偁傞傫偱偡偑丄僥僉僗僩僽儔僂僓偲偟偰桳柤側Lynx偱偼壔偗傞晹暘偑偁偭偨偐傜偱偡丅傑偨丄実懷揹榖側偳偺娐嫬偱偼Shift-JIS偺昁梫偑偁傝傑偡丅偝偰丄偙偺婰帠偱偼Shift-JIS偱曐懚偝傟偨暥帤楍傪僥僉僗僩VRAM偵彂偒偙傫偱昞帵偡傞偲偄偆偺偑戣栚側偺偱丄偦傟埲奜偺暥帤僐乕僪偵偼怺擖傝偟傑偣傫乮帺暘偱傕傢偐傜側偄偺偱乯丅
椺偊偽乽擫乿偲偄偆娍帤傪曐懚偟偰丄僶僀僫儕僄僨傿僞偱尒偰傒傑偡丅偡傞偲丄"94 4C"偲尵偆僶僀僩楍偱乮儚乕僪楍偱側偔乯曐懚偝傟偰偄傞偺偑暘偐傝傑偡丅偙傟傪JIS偱曐懚偟偰傒傑偡丅"1B 24 42 47 2D 1B 28 42"偲憹偊偨偺偑尒偰偲傟傞偐偲巚偄傑偡丅BASIC偺帪戙偐傜巊傢傟偰偄傞曽偼偛懚抦偱偟傚偆偑丄kanji-in(KI)/kanji-out(KO)偵憡摉偡傞僐乕僪乮KI/KO偦偺傕偺偱偼側偄乯偑偮偄偰偄傞傢偗偱偡丅
尰嵼偱偼JIS僐乕僪偱曐懚偲偄偆尵梩偼JIS X 213偲偄偆暥帤廤崌偵廬偭偰柺嬫揰傪巜掕偟偰ISO-2022-JP偲偄偆晞崋壔曽幃偵廬偭偰暥帤傪偁傜傢偡僐乕僪傪妋掕偡傞偲偄偆堄枴偵側傝傑偡丅尦乆偼JIS偲偄偆柤慜傪娭偟偨婯奿偼JIS X 208偲偄偆婯奿偑偁傝丄偙傟偼94x94偺儅僗栚偺敔傪傂偲偮梡堄偟偰丄偦偺拞偵壗傜偐偺億儕僔乕偺尦偵娍帤傪媗傔崬傫偱偄偔偲偄偆婯奿偱偡丅偦偺敔偺拞偵偼慡妏僇僞僇僫丄慡妏傂傜偑側丄戞1悈弨娍帤丄戞2悈弨娍帤側偳偑奿擺偝傟偰偄傑偡丅乽擫乿偲偄偆娍帤偼10恑悢偱(39,13),16恑悢偱(27h,0Dh)偲偄偆嵗昗偱昞帵偱偒傑偡((1,1)偐傜奐巒偟傑偡丅)丅偙傟傪39嬫13揰偲昞尰偟傑偡丅
側偍丄戞3丄戞4悈弨娍帤側偳偼忋婰偺1屄偺敔偱偼擖傝偒傜側偄傢偗偱偡丅偙傟傪夵慞偟丄Shift-JIS僐乕僪偵傕峫椂偟偨JIS X 0208傪奼挘偟偨婯奿偱偁傞JIS X 0213(2000擭嶔掕)偱偼丄敔傪偄偔偮傕梡堄偡傞偙偲偵偟傑偟偨丅偦傟偧傟偺敔傪乽柺乿偲屇傃偦偺拞偵嬫偲揰偑偁傞偲偄偆峔憿偱偡丅傑偁丄98偱偼婥偵偟側偔偰偄偄偺偱偡偑丅
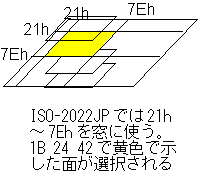 偝偰丄JIS X 208傪ASCII僐乕僪偲椉棫偝偣偨偄偲偄偆偙偲偵側傝傑偡丅偙傟偵搒崌偺傛偄傛偆偵丄ASCII僐乕僪偱偼惂屼僐乕僪偲偝傟傞00h偐傜20h傑偱傪旔偗偰21h偐傜7Eh傑偱偵偦偺敔偑尒偊傞乽憢乿傪愝偗丄僄僗働乕僾僔乕働儞僗偵傛傝憢偺岦偙偆偵尒偊傞柺傪慖戰偡傞婯奿偑ISO-2022-JP偵側傞傢偗偱偡偱偡丅"1B 24 42"偑戞堦悈弨暥帤偺懚嵼偡傞柺偑弌偰偔傞傛偆偵偟傠偲偄偆巜掕偵側傝傑偡丅
偝偰丄JIS X 208傪ASCII僐乕僪偲椉棫偝偣偨偄偲偄偆偙偲偵側傝傑偡丅偙傟偵搒崌偺傛偄傛偆偵丄ASCII僐乕僪偱偼惂屼僐乕僪偲偝傟傞00h偐傜20h傑偱傪旔偗偰21h偐傜7Eh傑偱偵偦偺敔偑尒偊傞乽憢乿傪愝偗丄僄僗働乕僾僔乕働儞僗偵傛傝憢偺岦偙偆偵尒偊傞柺傪慖戰偡傞婯奿偑ISO-2022-JP偵側傞傢偗偱偡偱偡丅"1B 24 42"偑戞堦悈弨暥帤偺懚嵼偡傞柺偑弌偰偔傞傛偆偵偟傠偲偄偆巜掕偵側傝傑偡丅
偙傟傑偱偺棳傟傪弍岅偱偄偆偲丄乽擫乿偲偄偆娍帤傪JIS X 0208偲偄偆暥帤廤崌偐傜39嬫13揰偵妋掕偟丄ISO-2022-JP偲偄偆晞崋壔曽幃偱偼"47 2D"偲偄偆僐乕僪傪妱傝摉偰丄僄僗働乕僾僔乕働儞僗傪偦偺慜屻偵偮偗偰"1B 24 42 47 2D 1B 28 42"偵偟偨偲偄偄傑偡丅傑偨丄乽擫乿偲偄偆娍帤傪39嬫13揰偵妋掕偟偨屻偵Shift-JIS偲偄偆晞崋壔曽幃偵傛傝丄"94 4C"偲偄偆僐乕僪偑妱傝摉偰傜傟偨偲偄偆偙偲偵側傝傑偡丅
偝偰丄忋偺JIS僐乕僪偱偼妋偐偵憢傪愗傝懼偊偰戲嶳偺暥帤傪巜掕偡傞偙偲偑偱偒傑偡丅偟偐偟丄摉帪偺尰幚栤戣偲偟偰偼丄暥帤偺愗傝懼偊偺偨傃偵kanji-in(KI)/kanji-out(KO)傪偮偗傞偺偼晄宱嵪偱偁傝傑偟偨丅傑偨丄暃師揑偵偼KI/KO偑壔偗傞偲偦偺屻偢偭偲壔偗壔偗忬懺偵側傞偲偄偆崲偭偨偙偲傕婲偒傑偡丅偦傟傪崕暈偟偨偺偑MS-DOS埲棃偱嵦梡偝傟偨Shift-JIS僐乕僪偵側傝傑偡丅姎傒嵱偄偰尵偆偲惂屼僐乕僪偲塸悢帤偲嶍彍僐乕僪偲敿妏僇僞僇僫傪彍偄偨偲偙傠偵娍帤偺1僶僀僩栚傪kanji-in(KI)偺堄枴傕娷傔偰柍棟傗傝墴偟崬傫偱偟傑偆偲偄偆傕偺偱偡丅偙傟偵傛傝丄廬棃偺敿妏暥帤偲偺嫟懚偑偱偒傞偙偲偵側傝傑偡丅梋択偱偡偑巹偼偙傟傪尒傞偲崙摴偲巗摴偺岎嵎揰傪屪偄偱1偮偺價儖傪寶偰傞偲偄偆傛偆側憐憸傪偟偰偟傑偄傑偡丅(^^;
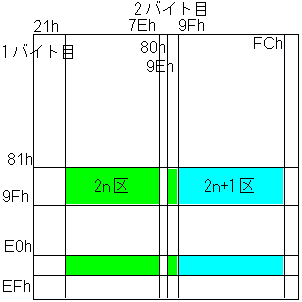 傑偢戞1僶僀僩栚偼忋弎偺傛偆偵惂屼僐乕僪偲塸悢帤偲嶍彍僐乕僪偲敿妏僇僞僇僫傪旔偗傞娭學忋梋傝戝偒偔庢傟側偄偐傜丄94捠傝傕偺抣偺巜掕偼偱偒偢偵敿暘偺47捠傝偺巜掕偺傒偟傑偡丅師偵1僶僀僩栚偱巜掕偟懝偹偨暘傪2僶僀僩栚偱曗偄傑偡丅2僶僀僩栚偱偼塸悢帤偲僇僞僇僫偼旔偗傑偣傫丅偡傞偲94x2埲忋偺抣傪巜掕偱偒傑偡丅偦偺曽朄傪摜傑偊偰丄乽嬫/2乿傪81h乣9Fh偲僇僞僇僫傪旘偽偟偰E0h乣EFh偺寁47屄偺傾僪儗僗偵妱傝摉偰傑偡丅2僶僀僩栚偼乽嬫%2乿偑0丄偮傑傝嬼悢嬫偺偲偒偵偼40h乣7Eh偲嶍彍僐乕僪傪旘偽偟偰80h乣9Eh偺寁94屄偺傾僪儗僗偵丄乽嬫%2乿偑1丄偮傑傝婏悢嬫偺偲偒偵偼9Fh乣FCh偺94屄偺傾僪儗僗偵揰偺彫偝偄傎偆偑彫偝偄傾僪儗僗偵側傞傛偆偵妱傝摉偰傑偡丅
傑偢戞1僶僀僩栚偼忋弎偺傛偆偵惂屼僐乕僪偲塸悢帤偲嶍彍僐乕僪偲敿妏僇僞僇僫傪旔偗傞娭學忋梋傝戝偒偔庢傟側偄偐傜丄94捠傝傕偺抣偺巜掕偼偱偒偢偵敿暘偺47捠傝偺巜掕偺傒偟傑偡丅師偵1僶僀僩栚偱巜掕偟懝偹偨暘傪2僶僀僩栚偱曗偄傑偡丅2僶僀僩栚偱偼塸悢帤偲僇僞僇僫偼旔偗傑偣傫丅偡傞偲94x2埲忋偺抣傪巜掕偱偒傑偡丅偦偺曽朄傪摜傑偊偰丄乽嬫/2乿傪81h乣9Fh偲僇僞僇僫傪旘偽偟偰E0h乣EFh偺寁47屄偺傾僪儗僗偵妱傝摉偰傑偡丅2僶僀僩栚偼乽嬫%2乿偑0丄偮傑傝嬼悢嬫偺偲偒偵偼40h乣7Eh偲嶍彍僐乕僪傪旘偽偟偰80h乣9Eh偺寁94屄偺傾僪儗僗偵丄乽嬫%2乿偑1丄偮傑傝婏悢嬫偺偲偒偵偼9Fh乣FCh偺94屄偺傾僪儗僗偵揰偺彫偝偄傎偆偑彫偝偄傾僪儗僗偵側傞傛偆偵妱傝摉偰傑偡丅
僥僉僗僩VRAM偼ISO-2022-JP偲斾傋傞偲暘偐傝傗偡偄偱偡偑丄姰慡偵偦偺僐乕僪傪彂偗偽偦傟偵墳偠偨僼僅儞僩僷僞乕儞偑曉偝傟傞偲偄偆傢偗偱偼側偄偱偡丅傑偨丄僄僗働乕僾僔乕働儞僗偼晄梫偱偡丅PC-9800僔儕乕僘偱偼僙僌儊儞僩A000h-A200h偑僥僉僗僩VRAM偱僙僌儊儞僩A200h-A400h偑傾僩儕價儏乕僩僄儕傾偵側偭偰偄傑偡偹丅
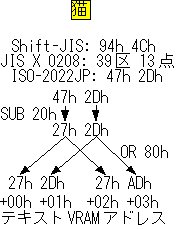 孞傝曉偟傑偡偑丄乽擫乿偺ISO-2022-JP偱偺僄僗働乕僾僔乕働儞僗傪彍偄偨僐乕僪偼"47h 2Dh"偱偡丅壓埵僶僀僩偐傜20h傪堷偒傑偡偲丄乽擫乿偩偲"27h 2Dh"偵側傝傑偡丅傑偢偙傟傪1僶僀僩栚偑嬫偱壓埵僶僀僩丄2僶僀僩栚偑揰偱忋埵僶僀僩偵側傞傛偆偵偟丄儚乕僪扨埵傑偨偼僶僀僩扨埵偱僥僉僗僩VRAM偵彂偒偙傒傑偡丅偦偺捈屻偺僥僉僗僩VRAM偺2僶僀僩偵偼2僶僀僩栚偺BIT7傪棫偰偰摨偠暔傪彂偒偙傒傑偡丅乽擫乿偩偲"27h ADh"偵側傝傑偡偹丅
孞傝曉偟傑偡偑丄乽擫乿偺ISO-2022-JP偱偺僄僗働乕僾僔乕働儞僗傪彍偄偨僐乕僪偼"47h 2Dh"偱偡丅壓埵僶僀僩偐傜20h傪堷偒傑偡偲丄乽擫乿偩偲"27h 2Dh"偵側傝傑偡丅傑偢偙傟傪1僶僀僩栚偑嬫偱壓埵僶僀僩丄2僶僀僩栚偑揰偱忋埵僶僀僩偵側傞傛偆偵偟丄儚乕僪扨埵傑偨偼僶僀僩扨埵偱僥僉僗僩VRAM偵彂偒偙傒傑偡丅偦偺捈屻偺僥僉僗僩VRAM偺2僶僀僩偵偼2僶僀僩栚偺BIT7傪棫偰偰摨偠暔傪彂偒偙傒傑偡丅乽擫乿偩偲"27h ADh"偵側傝傑偡偹丅
傑偁丄悽偺拞傕偭偲岠棪揑側僐乕僪傪彂偄偰偄傞恖傕偍傜傟傞傛偆偱偡偑丄巹偑彂偄偨偺偼師偺傛偆側僐乕僪偱偡丅偄偪偄偪偙傫側僐乕僪偵懠恖偺棙梡惂尷傪偮偗傞偺傕偁傎傜偟偄偺偱丄巊偄偨偄偲偄偆曽偼彑庤偵巊偭偰偔偩偝偭偰寢峔偱偡丅楢棈傕偄傝傑偣傫丅偨偩丄怱柍偄恖偵攔懠揑側棙梡傪栚揑偲偟偨挊嶌尃傪庡挘偝傟傞偲崲傝傑偡偺偱丄挊嶌尃偼庡挘偟偰偍偒傑偡丅寁20僶僀僩偺僐乕僪偵側傝傑偡丅
;Shift-JIS僐乕僪偺1僶僀僩栚丄偮傑傝嬫/2偑AL丄 ;2僶僀僩栚丄偮傑傝嬫%2偲揰偑AH偵奿擺偝傟偰偄傞忬懺 INC AH JNS SK1 DEC AH SK1: ADD AH,61h;[9Fh,FCh]->[00h,5Dh] [41h,9Eh]->[A2h,FFh] JC SK2 SUB AH,0A2h;[A2h,FFh]->[00h,5Dh] SK2: RCL AL,01h;[81h,9Fh]->[02h,3Eh] [E0h,EFh]->[C0h,DEh] AND AL,7Fh;[02h,3Eh]->[02h,3Eh] [C0h,DEh]->[40h,5Eh]乮楢寢両乯 ; ADD AX,211Fh ;Shift-JIS->ISO2022-JP曄姺嵪傒 ; SUB AL,20h;VRAM彂偒偙傒偺偨傔偺慬抲 ADD AX,20FFh;忋偺僐儊儞僩傾僂僩偟偨峴傪崌傢偣偨 ; STOSW摍偲懕偔丒丒丒摉偨傝慜偱偡偑DWORD傾僋僙僗嬛巭 ; OR AH,80h ; STOSW